 RoSHI: A Versatile Robot-oriented Suit for Human Data
In-the-Wild
RoSHI: A Versatile Robot-oriented Suit for Human Data
In-the-Wild
Walk
Tennis
Scaling up robot learning will likely require human data containing rich and long-horizon interactions in the wild. Existing approaches for collecting such data trade off portability, robustness to occlusion, and global consistency. We introduce RoSHI, a hybrid wearable that fuses low-cost sparse IMUs with the Project Aria glasses to estimate the full 3D pose and body shape of the wearer in a metric global coordinate frame from egocentric perception. This system is motivated by the complementarity of the two sensors: IMUs provide robustness to occlusions and high-speed motions, while egocentric SLAM anchors long-horizon motion and stabilizes upper body pose. We collect a dataset of agile activities to evaluate RoSHI. On this dataset, we generally outperform other egocentric baselines and perform comparably to a state-of-the-art exocentric baseline (SAM3D). Finally, we demonstrate that the motion data recorded from our system are suitable for real-world humanoid policy learning.
RoSHI is a hybrid wearable system that combines nine low-cost IMU trackers with Project Aria glasses to capture synchronized (i) 3D body pose, (ii) egocentric RGB video, and (iii) a globally consistent 6-DoF root trajectory. As illustrated in the figure below, the two sensing modalities are complementary: IMUs provide robust local body orientation estimates under occlusion and fast motion, while egocentric SLAM from Aria anchors global motion over long horizons and stabilizes upper-body pose.
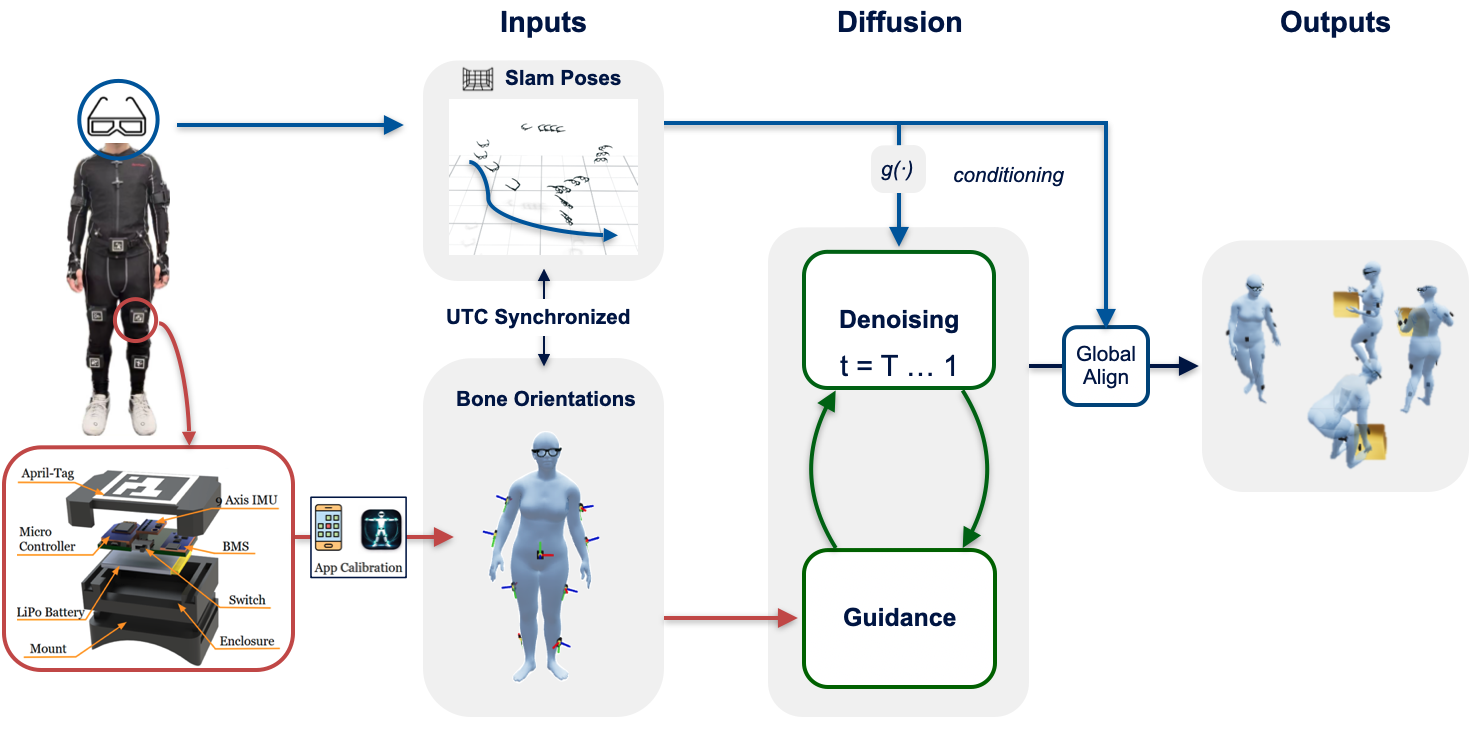
We propose a vision-assisted calibration procedure that removes the need for box calibration or predefined poses. Each IMU is rigidly attached to an AprilTag, and a short 20–40 second handheld iPhone video is used to jointly estimate (i) sensor-to-bone alignment and (ii) cross-sensor heading consistency. Specifically, we combine AprilTag detections with per-frame body pose estimates from SAM 3D Body to recover consistent rotations between the IMU frames and the SMPL skeleton. This enables fast, on-body calibration and supports re-calibration without removing the sensors.
We generate full-body pose using the EgoAllo diffusion model conditioned on the 6-DoF headset trajectory from Aria SLAM. Instead of relying on vision-based hand cues, we guide the diffusion process using bone orientations derived from IMU measurements. We enforce three complementary constraints during inference: (i) direct supervision of observable joint angles (e.g., elbows, hips, knees), (ii) consistency of relative orientations between key body segments (e.g., pelvis and shoulders), and (iii) temporal smoothness of pelvis-relative joint rotations across consecutive frames. This combination enables robust pose reconstruction under visual occlusion while preserving globally consistent motion.
We tested RoSHI in unconstrained in-the-wild environments. Below are two sample sequences, each showing the synchronized egocentric RGB, recovered human pose, and the 3D scene reconstruction (point cloud) from Aria SLAM.
Walk
Tennis
We evaluate RoSHI on 11 motion sequences across three datasets covering in-place motions, locomotion with global translation, and agile sports-like activities. RoSHI achieves the best mean per-joint position error (MPJPE) across all three datasets and the best joint angle error (JAE) on two of three, showing consistent improvements in both global joint localization and articulated pose reconstruction over egocentric baselines.
| Method | Egocentric | Dataset 1 | Dataset 2 | Dataset 3 | |||
|---|---|---|---|---|---|---|---|
| MPJPE (cm) | JAE (deg) | MPJPE (cm) | JAE (deg) | MPJPE (cm) | JAE (deg) | ||
| SAM3D | ✗ | 10.3 | 10.5 | 10.5 | 10.7 | 21.6 | 11.2 |
| IMU-only (naive) | ✓ | 16.7 | 12.6 | 18.8 | 12.2 | 16.1 | 8.9 |
| IMU + EgoAllo root | ✓ | 12.7 | 12.5 | 11.9 | 12.2 | 12.5 | 8.7 |
| EgoAllo | ✓ | 10.6 | 15.6 | 10.0 | 14.1 | 11.7 | 17.5 |
| RoSHI (ours) | ✓ | 9.6 | 12.0 | 9.9 | 11.0 | 10.3 | 15.6 |
MPJPE is computed in the OptiTrack world frame; JAE is computed from parent–child bone directions (independent of global/root pose). SAM3D relies on an external calibrated camera and is therefore not a fair baseline (shown in gray).
Walk / March / Jog / Run
Stretch / Boxing / Bow / Wave
Jumping Jack / Squat / One-Leg Squat
Pick Up Box
Walk / Say Hi / Walk
Pickup / Walk Around
Walk / Jog Back and Forth
Jump Around
Sliding
Tennis
Ball Throwing / Catching
We retarget RoSHI motion data to a Unitree G1 humanoid and train motion-mimic tracking policies. The policies transfer to the real robot with stable, dynamically consistent whole-body behaviors, showing that RoSHI data is ready for humanoid policy learning and sim-to-real deployment.
Tennis
Jump
The RoSHI system is organized into modular repositories. All repositories will be publicly available.
RoSHI Core Algorithm
CoreFull pose estimation pipeline: IMU-guided EgoAllo diffusion, sensor fusion, calibration processing, and SMPL body model output.
RoSHI-App
CalibrationiOS app for calibrating the RoSHI wearable system. Captures RGB video with real-time AprilTag detection and synchronizes with 9 body-mounted IMU sensors over LAN.
RoSHI-Hardware
HardwareHardware design files, 3D-printable enclosures, BOM, and ESP32 firmware for the 9 wireless IMU trackers (BNO085-based, 100 Hz).
Refer to the documentation for detailed setup instructions.
For questions, please reach out to the area lead.
For bugs and feature requests, please prefer opening an issue on the relevant repository.
This work was supported by DARPA under Agreement No. HR0011-24-9-0430, and the Swiss National Science Foundation under Grant No. 225354. We thank the Meta Aria team for their support and for providing access to the Aria hardware and software infrastructure. We also thank Nalini Jain for testing the codebase and recording qualitative evaluation videos, and Paul (Sanghyub) Lee from Nadia's lab for assisting with the collection of ground-truth human motion data using OptiTrack.